
 바이러스와 사회: 2
바이러스와 사회: 2
도시는 이동의 결사체다. 동선의 효율을 높이기 위해, 혹은 편의를 유지하기 위해 매순간 어마어마한 사회적 비용을 지불하는 집합체다. 도시 교통이 생물체의 혈류에 비유되곤 하는 것은 시각적 유사성을 넘어 실제 그 멈춤이나 정체가 곧바로 도시 기능의 마비를 가져오기 때문이다. 그런 도시에서 살아온 현대인에게 이동의 제약은 기능적 마비와 더불어 기본권의 제약, 심리적 구속이라는 견디기 힘든 느낌을 가져온다. covid-19에 대응한 사회적 거리두기 조치의 핵심은 외부 일상활동의 제한, 동선의 제약인데, 이는 도시의 구조와 정신에 정면으로 반한다. 그러므로 선량한 시민들과 방역당국의 바람에도 불구하고 이동을 제한하는 조치가 완벽하게 이행되리라고 기대하는 것은 불가능하거나 적어도 자연스럽지 않다. 그럼에도 불구하..
 바이러스와 사회: 1
바이러스와 사회: 1
"군중은 이미지로만 사고 가능한 바 이미지에만 감응한다. 그들을 겁주거나 매혹하여 행동의 동기를 부여하는 것은 오직 이미지밖에 없다. " Crowds being only capable of thinking in images are only to be impressed by images. It is only images that terrify or attract them and become motives of action. - Le Bon (1895), The Crowd: A Study of the Popular Mind 바다에 들어가 파도를 몸으로 경험해보면 파도의 성질이 눈짐작과 얼마나 다른지 깨닫게 된다. 코로나바이러스가 말그대로 인류를 휩쓸고 다니는 시국을 지켜보며, 처음 바다에서 파도를 경험한 그..
 서울시 공공자전거 따릉이: 12. 신뢰, 기만
서울시 공공자전거 따릉이: 12. 신뢰, 기만
지난 글에서 지적했던 데이터 오류에 대해 data.seoul에 직접 문의했다. 아마도 서울시설공단 측에서 건너왔을 답변은 아래와 같다. 현장 자전거에 부착된 단말기는 주행거리를 계산하는 기능이 있는데, 현장 단말기는 한정된 배터리로 동작되기 위해서 저전력 설계가 되어 있습니다. 1분마다 한번씩 wake up해서 주행거리를 덧셈하게 되는데, CPU 데이터의 오버플로우가 발생하게 되면, 주행거리가 실제보다 짧게 나오는 경우가 생깁니다. 외부환경(비, 햇빛)에 의해서 운용될 때 노후화로 인하여 주행거리 계산 기능이 100%이 정확도를 갖지 못하는 현실적인 어려움이 있습니다. 한마디로, 자전거에 장착된 회로 성능과 내구도가 좋지 못해 어떤 주행거리 데이터는 엉터리일 수 있다는 것이다. 그리고 행간에는 이것이 뭔..
 서울시 공공자전거 따릉이: 11. epilogue
서울시 공공자전거 따릉이: 11. epilogue
지난번 O-D 지도를 만든 업보로, 2017년 전체 데이터도 마찬가지 방식으로 지도에 펴보지 않을 수 없게 되었다. 사실 ‘마찬가지 방식’은 될 수 없다. 선의 개수가 31.2만 개에서 415.6만 개로 13배 이상 늘어났기 때문이다. 아래에서 보겠지만, 30만 개까지는 봐줄 만하다 쳐도 400만 개의 선을 종이 한 장 위에 그리면 어떻게 그리든 복잡해 보인다. 즉 이해 가능한 그림을 그리려면 우선 데이터를 어떤 식으로든 쪼개어야 한다. 나누어 그려야 하다는 것은 그만큼 해야 하는 설명의 양도 늘어난다는 뜻이 된다. 그런데 막상 적다 보니 할 이야기가 한도 끝도 없이 많다. 실은 그동안 내 글 자체가 그랬다.. 보이려던 건 그림 몇 장인데 결과적으로는 글 쓰는 데 너무 많은 에너지를 소모하게 된다. 당초..
 서울시 공공자전거 따릉이: 10. 데이터 탐색과 시각화 2
서울시 공공자전거 따릉이: 10. 데이터 탐색과 시각화 2
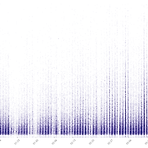
며칠 전, data.seoul이 데이터를 한꺼번에 올리지 않고 굳이 끊어먹고 있다는 핀잔 섞인 글을 올렸는데, 불과 몇 시간 후 나머지 데이터가 올라왔다. 약오르게.아무튼 댓글 제보에 감사하며. 업데이트된 데이터를 반영, 앞의 글에서와 동일한 방법으로 서비스 시작 시점부터 2018년 1분기까지의 대여기록 764.5만 건을 scatterplotting 해보았다. 2015년 9월 19일 - 2018년 1분기 대여내역의 이동거리에 따른 scatterplot. 전체적으로는, 사실 몇 달 전 대여소 기준 데이터를 가지고 7편의 글을 작성하면서 탐색했던 바를 재확인해주는 그림이다. 다만 이 그림은 색의 농담 차이를 어떻게 이해할 것인가에 따라 여러 해석이 가능하기 때문에 자기완결적이지 않다. 가령, 2017년 연간..
 서울시 공공자전거 따릉이: 9. 데이터 탐색과 시각화
서울시 공공자전거 따릉이: 9. 데이터 탐색과 시각화
지난 글에서는 데이터를 열자마자 곧장 지도로 들고 달려가버렸다. O-D 데이터는 아니어도 이전 글들에서 따릉이 이용패턴에 대한 윤곽은 이미 잡았다고 생각하기도 했고, 일단 내 마음이 급했다.대부분의 경우 기술통계량(descriptive statistics) 등 기본적인 데이터 이해 없이 시각화에 나서는 건 바람직하지 않거니와 실상 가능하지도 않다. 비유하자면 신체 측정도 하지 않고 눈대중으로 맞춤정장을 만들려는 꼴이다. 무엇을 디자인할지 정하지 않고 디자인하려는 것. 그런데 사실 시각화라는 단어를 어떻게 규정하느냐에 따라 위의 비판은 틀린 것일 수 있다. 시각화란 무엇인가? 반드시 현란하고 고도로 정제된 것만이 시각화인가. 스케치북에 크레용으로 그린 일과표, 수학문제를 풀려고 그린 함수곡선도 시각화가 아..
 서울시 공공자전거 따릉이: 8. O-D
서울시 공공자전거 따릉이: 8. O-D
서울시가 따릉이의 대여소별 데이터에 이어 지난 5월 자전거별 대여이력을 공개했다. 처음 data.seoul에 올라온 데이터 제목을 보고는 흥분감을 느끼며 다운로드를 시작했다. 대여자 정보와 이동경로가 포함되어 있는 줄 기대했던 것이다. 따릉이는 회원제이므로 모든 대여이력에는 이용자의 특성 관련 사항이 결합될 수 있다. 게다가 자전거에 GPS가 내장되어 있기에 서울시 서버에는 따릉이 이용자가 이용한 이동경로까지 저장되어 있을 것이다.그러나 서울시의 개인정보 노출 공포증 때문인지, 아니면 대부분이 데이터를 소화 못할 것을 걱정해준 때문인지, 그런 데이터는 싹 날아가 있다. 공개된 데이터셋은 자전거 고유번호, 분 단위의 대여 시작 및 반납 시간, 대여 시작 및 반납 장소, 주행거리로 이루어져 있다. 그마저도 ..
 단기체류 외국인: 4. WYSIWYG?
단기체류 외국인: 4. WYSIWYG?
앞의 #2 글에서 보았던 관광지도의 부분도 영역을 주간(9-21시) 핫스팟 지도 위에 올려본 결과는 다음과 같다. visitseoul.kr 관광지도의 강북지역 표시영역과 주간 핫스팟 영역의 중첩. 강북부터 보자. 사대문안 지역의 경우 부분도가 다루는 영역이 2018년 4월의 핫스팟과 비교적 잘 일치하고 있다. 인사동-북촌과 명동을 선택 강조하는 것이 최선인지 궁금하지만, 이 분석만으로는 알 수 없다. 이태원 지역에 대해서는 약간 짜게 넣은 감이 없지는 않지만 큰 불일치는 없는 것으로 보인다.반면 홍대앞 부분도는 현재의 핫스팟에 비하면 상당히 협소한 영역만을 다루고 있음을 알 수 있다. 이 핫스팟의 북쪽, 대략 경의·중앙선 공원이 지나가는 넓은 영역이 주/야간을 막론하고 외국인에게 인기 있는 지역이지만 관..
 단기체류 외국인: 3. 핫스팟
단기체류 외국인: 3. 핫스팟
이 분석기법을 사용하면서도 실증적 기반이 탄탄하지 않다는 이야기를 덧붙이는 이유는, 이 도구를 사용하기 위해 선언해야 하는 spatial weights matrix(마음에 드는 번역은 아니지만 보통 ‘공간가중행렬’)의 기준이 뚜렷하지가 않기 때문이다.비공간 데이터와 구별되는 공간 데이터의 특성은 “모든 것은 서로 연관되어 있지만, 멀리 있는 것들보다는 가까이 있는 것들과 연관성이 높다”는 원칙론적 명제로 함축된다. 이 명제에 동의함으로써 각각의 관찰 결과가 상호 독립적임을 전제하는 일반적 통계 접근은 불합리해지고, 대신 시계열분석(time-series analysis)에서 즐겨 쓰는 자기상관성(autocorrelation) 개념이 필요해진다. SWM은 공간 데이터에 자기상관성을 대입함에 있어 ‘자기’를 ..
 단기체류 외국인: 2. 공간통계적 쓸모
단기체류 외국인: 2. 공간통계적 쓸모
앞에서 신나게 까댔는데. 그러면 이 ‘데이터’는 그저 무쓸모한, 심지어 현상을 호도하는 숫자놀음인가. 그건 다시금, 우리가 이 데이터의 해상도에 어느 정도 기대를 거느냐에 따라 그럴 수도 아닐 수도 있다.가령 이런 접근은 확실히 문제가 있다는 생각이다: 서울시는 예비창업주들을 위해 이 내국인 생활인구 모델링 데이터를 토대로 서울 전역의 도로별 유동인구 정보를 고해상도로 제공하고 있다. 그러니까 신촌역 남쪽 골목상권인 서강로20길의 주중 14-16시 20대 유동인구가 600-750명이라고 알려주는 식이다. 물론 창업자가 이것만 보고서 결정을 내리지는 않으리라 믿지만, 가게 앞 유동인구는 입지 선정의 핵심 고려사항이고 개인이 객관적으로 파악하기 어렵기 때문에 눈길이 갈 수밖에 없다. 그런 자료가 이렇게까지나..
- Total
- Today
- Yesterday