
 서울시 공공자전거 따릉이: 12. 신뢰, 기만
서울시 공공자전거 따릉이: 12. 신뢰, 기만
지난 글에서 지적했던 데이터 오류에 대해 data.seoul에 직접 문의했다. 아마도 서울시설공단 측에서 건너왔을 답변은 아래와 같다. 현장 자전거에 부착된 단말기는 주행거리를 계산하는 기능이 있는데, 현장 단말기는 한정된 배터리로 동작되기 위해서 저전력 설계가 되어 있습니다. 1분마다 한번씩 wake up해서 주행거리를 덧셈하게 되는데, CPU 데이터의 오버플로우가 발생하게 되면, 주행거리가 실제보다 짧게 나오는 경우가 생깁니다. 외부환경(비, 햇빛)에 의해서 운용될 때 노후화로 인하여 주행거리 계산 기능이 100%이 정확도를 갖지 못하는 현실적인 어려움이 있습니다. 한마디로, 자전거에 장착된 회로 성능과 내구도가 좋지 못해 어떤 주행거리 데이터는 엉터리일 수 있다는 것이다. 그리고 행간에는 이것이 뭔..
 서울시 공공자전거 따릉이: 10. 데이터 탐색과 시각화 2
서울시 공공자전거 따릉이: 10. 데이터 탐색과 시각화 2
며칠 전, data.seoul이 데이터를 한꺼번에 올리지 않고 굳이 끊어먹고 있다는 핀잔 섞인 글을 올렸는데, 불과 몇 시간 후 나머지 데이터가 올라왔다. 약오르게.아무튼 댓글 제보에 감사하며. 업데이트된 데이터를 반영, 앞의 글에서와 동일한 방법으로 서비스 시작 시점부터 2018년 1분기까지의 대여기록 764.5만 건을 scatterplotting 해보았다. 2015년 9월 19일 - 2018년 1분기 대여내역의 이동거리에 따른 scatterplot. 전체적으로는, 사실 몇 달 전 대여소 기준 데이터를 가지고 7편의 글을 작성하면서 탐색했던 바를 재확인해주는 그림이다. 다만 이 그림은 색의 농담 차이를 어떻게 이해할 것인가에 따라 여러 해석이 가능하기 때문에 자기완결적이지 않다. 가령, 2017년 연간..
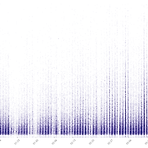 서울시 공공자전거 따릉이: 9. 데이터 탐색과 시각화
서울시 공공자전거 따릉이: 9. 데이터 탐색과 시각화
지난 글에서는 데이터를 열자마자 곧장 지도로 들고 달려가버렸다. O-D 데이터는 아니어도 이전 글들에서 따릉이 이용패턴에 대한 윤곽은 이미 잡았다고 생각하기도 했고, 일단 내 마음이 급했다.대부분의 경우 기술통계량(descriptive statistics) 등 기본적인 데이터 이해 없이 시각화에 나서는 건 바람직하지 않거니와 실상 가능하지도 않다. 비유하자면 신체 측정도 하지 않고 눈대중으로 맞춤정장을 만들려는 꼴이다. 무엇을 디자인할지 정하지 않고 디자인하려는 것. 그런데 사실 시각화라는 단어를 어떻게 규정하느냐에 따라 위의 비판은 틀린 것일 수 있다. 시각화란 무엇인가? 반드시 현란하고 고도로 정제된 것만이 시각화인가. 스케치북에 크레용으로 그린 일과표, 수학문제를 풀려고 그린 함수곡선도 시각화가 아..
 서울시 공공자전거 따릉이: 8. O-D
서울시 공공자전거 따릉이: 8. O-D
서울시가 따릉이의 대여소별 데이터에 이어 지난 5월 자전거별 대여이력을 공개했다. 처음 data.seoul에 올라온 데이터 제목을 보고는 흥분감을 느끼며 다운로드를 시작했다. 대여자 정보와 이동경로가 포함되어 있는 줄 기대했던 것이다. 따릉이는 회원제이므로 모든 대여이력에는 이용자의 특성 관련 사항이 결합될 수 있다. 게다가 자전거에 GPS가 내장되어 있기에 서울시 서버에는 따릉이 이용자가 이용한 이동경로까지 저장되어 있을 것이다.그러나 서울시의 개인정보 노출 공포증 때문인지, 아니면 대부분이 데이터를 소화 못할 것을 걱정해준 때문인지, 그런 데이터는 싹 날아가 있다. 공개된 데이터셋은 자전거 고유번호, 분 단위의 대여 시작 및 반납 시간, 대여 시작 및 반납 장소, 주행거리로 이루어져 있다. 그마저도 ..
 서울시 공공자전거 따릉이 #7
서울시 공공자전거 따릉이 #7
다음으로 넘어가기 전에 따릉이 데이터를 인구 데이터 위에 올려 보았다. 활용할 인구 데이터는 data.seoul의 생활인구 (내국인) 데이터셋이다. 생활인구는 ‘센서스로 파악된 주거인구가 실제 서울이 서비스하는 인구를 대변하지 못한다’는 전제 하에 최근 서울시가 야심차게 내놓은 데이터셋인데, KT 데이터를 활용해 매시간 서울의 센서스 집계구별 생활인구를 연령별로 추정하였다. 이것은 이론상 매일의 인구 분포 패턴을 12,870,816개 (19153개 집계구 × 14개 연령대 × 2개 성별 × 24시간) 에 달하는 숫자로 표현하는 고해상도의 인구 데이터다. 게다가 외국인 데이터는 별도로 산출된다. 이렇듯 생성 취지도 분명하고 해상도도 어마어마하기에 어떤 다른 데이터보다도 잠재력이 높은 편이다. 다만 설명서를..
 서울시 공공자전거 따릉이 #6
서울시 공공자전거 따릉이 #6
'따릉이 관리자 관점’에서 좀 더 파고 들어가면 이런 접근도 가능하다. 관련 기사 1 , 2를 보면 자전거를 재분배하는 작업이 소개된다. 굳이 다른 설명을 듣지 않아도, 관리자인 서울시설관리공단 일상업무의 중요하고 고된 부분을 차지하는 것이 재분배 업무임을 짐작할 수 있다. 그리고 자전거 분배팀이 나름의 패턴에 따라 움직인다는 이야기도 살짝 나온다. 다만 현장 취재 기사인 만큼 장기 패턴보다는 하루 안에서의 시간대별 패턴에 대한 내용이 주를 이룬다. 현재 공개된 따릉이 데이터는 1일 단위 대여소별로 누적된 대여건수와 반납건수이므로 시간대별 거치율의 변화는 알 수 없다. 그러나 일일 대여 대비 반납의 비율을 누적하는 것으로도 분배팀에게 참고가 될 만한 패턴이 나올 수 있겠다는 생각이 들었다. 따릉이 분배팀..
앞의 글 #1, #2에서 전체 대여량의 시계열 흐름을 그래프로 보았지만 사실 데이터셋의 애초 해상도인 1일 단위의 흐름이 본론에 해당할 것이다. 해서 대여망이 어느 정도 구축된 2017년의 대여소별 일일 대여건수 데이터를 시각화해 보았다. 앞의 그림으로는 알 수 없었던, 5월 이후 한강 이남과 동북부로 퍼져나간 대여소망이 금세 이용자층을 확보하는 모습이 일단 눈에 띈다. 그리고 여름 시기 점들의 깜빡임도 흥미롭다. 대여량이 하루하루 큰 폭으로 달라진다는 뜻인데, 공휴일 여부까지 포함시켜 본다면 앞의 회귀분석과는 다른 방식으로 비나 폭서와 같은 날씨요인 영향의 양상을 보여주는 신호가 될 것이다.그리고 따릉이 관리자 관점에서 생각해 보면, 각 점의 beat는 (민원이 올라오기 전에 적절히) 관리하기 골치 아..
 서울시 공공자전거 따릉이 #3
서울시 공공자전거 따릉이 #3
강수량과 자전거 이용 패턴의 관계 설정은 보다 까다롭다. 우선 강수량이라는 값이 자전거의 맥락에서 비/눈 오는 날의 환경을 잘 대변하는 지표인지 생각해볼 필요가 있다. 강수량 5mm인 날과 20mm인 날 중 언제 자전거 대여건수가 더 많았을지 추측하기는 쉽지만, 부슬비가 5mm 온 날과 소나기가 20mm 온 날 중에서 추측하기는 어렵다. 시간별 강수량 데이터를 반영한 가중치 산식을 동원해야만 보다 합리적인 지표가 만들어질 수 있을 것이다. 또 종로구 기상관측소 데이터의 ‘서울 강수량’으로서의 대표성에 한계도 있다.그러나 그런 한계를 감안하더라도 강수량 - 대여건수 관계는 신호가 너무 미약했다. 일일강수량 0.1mm 이상인 240일의 강수량(ln(prec)) - 따릉이 대여건수. lognormal 분포를 ..
 서울시 공공자전거 따릉이 #2
서울시 공공자전거 따릉이 #2
날씨요인에 관한 보다 자세한 분석을 위해 데이터를 좀 손봐야 했다.우선 데이터를 보내온 대여소가 30개 미만으로 대표성이 부족해 보이는 날을 제외하였다. 835일 중 이틀(2015년 10월 3일: 24개소, 2017년 7월 6일: 3개소)이 이에 해당된다. 그 외에도 유효한 집계로 보기 어려운 날이 몇 보이지만 자칫 데이터 마사지가 될까 봐 그냥 가지고 간다. 그리고 기온과 사용빈도의 관계를 반영하기로 하였다. 즉 일일평균기온 20도를 기준으로 사용빈도가 변화하는 패턴을 감안하여, 일일평균기온값을 20도로부터의 거리로 변환하여 변수로 사용하였다. t_m_20 = 20 - abs(temp_mean - 20)이렇게 하자 기온과 대여건수의 관계가 아래와 같이 좀 더 단순해졌다. 그리고 비/눈이 온 날과 그렇지..
 서울시 공공자전거 따릉이 #1
서울시 공공자전거 따릉이 #1
data.seoul에 흥미로운 데이터가 올라왔다. 2015년부터 운영된 서울의 공공자전거 서비스 ‘따릉이’의 대여소별 일일 대여량 데이터가 집계되어 제공되기 시작했다.사람들이 자전거를 어떻게 이용하고 있는지에 대한 데이터는 대중교통이나 자동차에 비해 정량화가 덜 이루어진 영역이다. 그러나 주요 도시에서 자전거 기반시설에 대한 공적인 관심과 투자가 중요해지면서 이 데이터에 매기는 가치도 높아지는 것은 당연한 수순이다. (뒤돌아보면 불과 10년 전 대중교통 및 자동차 데이터도 계수기 수준에서 크게 벗어나지 않았다.)자전거 및 보행 패턴 데이터 집적으로 무엇을 할 수 있는지에 대해서는 fitness-tracking 서비스인 Strava가 눈에 띄는 사례를 만들어가고 있다. 다만 이들의 노력이 그저 좋은 사례인..
- Total
- Today
- Yesterday